Theory of [Efficient] Computing: A branch of Theoretical Computer Science that deals with how quickly one can solve (compute) a given algorithm. The critical task is to analyze algorithms carefully based on their performance characteristics to make it computationally efficient.
Theory of Unified Algorithms: An emerging branch of Theoretical Statistics that deals with how efficiently one can represent a large class of diverse algorithms using a single unified semantics. The critical task is to put together different “mini-algorithms” into a coherent master algorithm.
For overall development of Data Science, we need both ANALYSIS + SYNTHESIS. However, it is also important to bear in mind the distinction between the two.

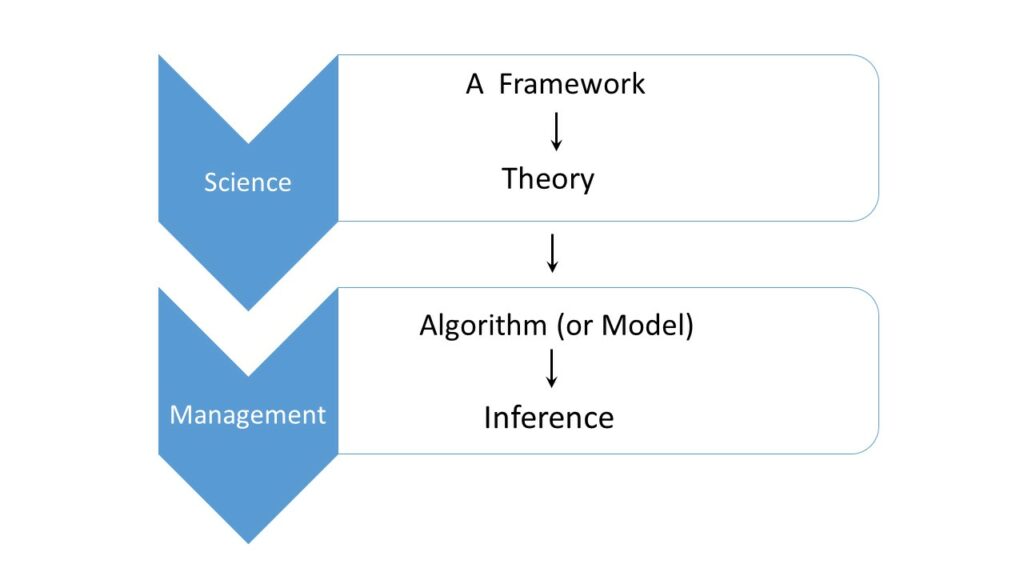 Hierarchy and branches of Statistical Science
Hierarchy and branches of Statistical Science
 ]]>
]]>